Kames - Presentation Notes¶
Navigácia k jednotlivým snímkam¶
- Paralelizácia v jazyku C#
- C# ako platforma pre paralelné programovanie
- Paralelizácia v C#
- Task Parallel Library (TPL)
- Sekvenčné a paralelné spracovanie pomocou ForEach
- Riadenie počtu vlákien pomocou For
- Paralelné spracovanie pomocou Task
- Paralelné spracovanie pomocou PLINQ
- Synchronizácia vlákien - štruktúry a synchronizátory
- Paralelné spracovanie pomocou lock
- Paralelné spracovanie pomocou semaphore (async)
- Paralelné spracovanie pomocou semaphore (sync)
- Úloha 3: Mandelbrot set
- Čo je Mandelbrotova množina
- Ako funguje Mandelbrotov algoritmus
- Divergencia a správanie iterácií
- Mandelbrotova množina v komplexnej rovine
- Nastavenie experimentu a hardvérová konfigurácia
- Vstup / Výstup
- Sekvenčná implementácia
- Profilovanie sekvenčnej verzie
- Profilovanie paralelnej verzie
- Paralelná implementácia
- Výsledky meraní
- Výsledky meraní
- Výsledky meraní
- Výsledky meraní
- Záver
1. Paralelizácia v jazyku C¶

Note 1
V tejto prezentácii sa budeme venovať paralelizácii v jazyku C#, konkrétne tomu, aké nástroje .NET ponúka na paralelné spracovanie a aký praktický prínos majú.
2. C# ako platforma pre paralelné programovanie¶

Note 2
C# v rámci .NET platformy ponúka veľmi silnú podporu pre paralelné spracovanie. Medzi najvýznamnejšie výhody pre programátora patria jednoduché vytváranie paralelných úloh vyššia úroveň abstrakcie. To v praxi znamená, že sa viem sústrediť viac na logiku algoritmu a menej na technické detaily plánovania vlákien. Dôležité je, že programátor sa nemusí starať o nízkoúrovňovú správu vlákien, pretože runtime disponuje automatickým riadením Thread Poolu. Ten dynamicky prispôsobuje počet aktívnych vlákien aktuálnej záťaži a počtu jadier CPU.
3. Paralelizácia v C¶
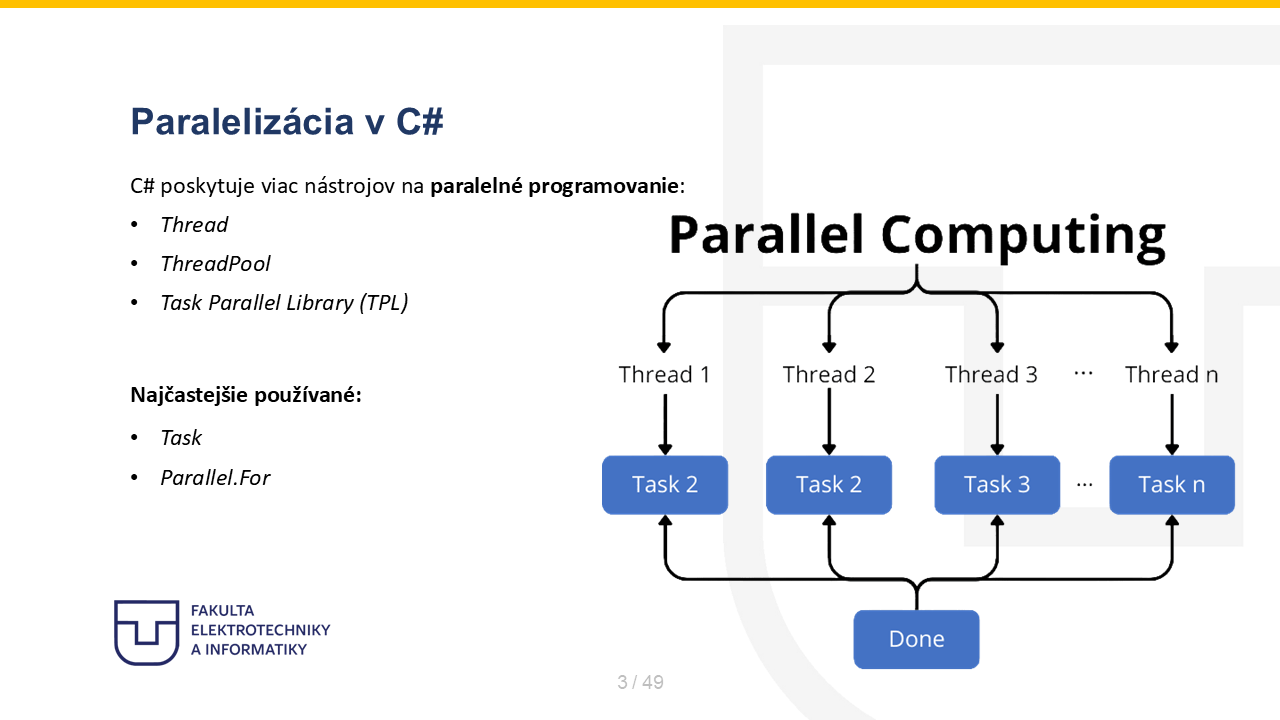
Note 3
Pokiaľ ide o nástroje, na tomto slide sú vypísané hlavné nástroje. Prvým je Thread, čo je najnižšia úroveň - tam si vlákno riadim manuálne. ThreadPool je skupina pripravených vlákien, ktorú .NET udržiava v rámci runtime a používa ju na vykonávanie úloh bez nutnosti stále vytvárať nové vlákna. Task Parallel Library, teda TPL, je vyššia vrstva nad tým, ktorá sa dnes používa najčastejšie. V rámci TPL sa najčastejšie používajú Task a Parallel.For, najmä pri úlohách, kde je možné spracúvať veľa nezávislých iterácií paralelne.
4. Task Parallel Library (TPL)¶

Note 4
Hlavným nástrojom paralelizmu v .NET je TPL (Task Parallel Library), ktorá zjednodušuje implementáciu paralelného spracovania v aplikáciách. Knižnica TPL sa nachádza v menných priestoroch System.Threading, System.Threading.Tasks. Zahŕňa dátovú paralelizáciu cezParallel.For/ForEach, úlohovú paralelizáciu cez Tasks a paralelné spracovanie dotazov cez PLINQ. TPL na pozadí inteligentne plánuje úlohy tak, aby sa minimalizoval overhead spojený s vytváraním vlákien a maximalizovalo využitie všetkých dostupných jadier procesora. Toto je dôležité aj z pohľadu škálovania. Ak aplikácia beží na inom procesore s iným počtom jadier, TPL vie tomu spravidla prispôsobiť plánovanie lepšie než ručne napísané pevné riešenie.
5. Sekvenčné a paralelné spracovanie pomocou ForEach¶

Note 5
Tu na konkrétnom príklade vidíme, aké jednoduché je prejsť od klasického sekvenčného spracovania k paralelizmu. V hornej časti vidíme klasický for cyklus, zatiaľ čo dole používame konštrukciu Parallel.ForEach z knižnice TPL. Prvý kód spracúva dáta jeden po druhom v hlavnom vlákne. Parallel.ForEach zoberie kolekciu data a funkciu Compute vykonáva paralelne. Počet vlákien tu neurčujeme manuálne; .NET runtime ich priraďuje dynamicky podľa aktuálneho stavu ThreadPoolu. Praktickým výsledkom je výrazné zrýchlenie pri veľkých dátach.
6. Riadenie počtu vlákien pomocou For¶

Note 6
Niekedy však potrebujeme mať nad paralelným vykonávaním väčšiu kontrolu, napríklad limitovať počet vlákien. Tento slide ukazuje Parallel.For, teda paralelnú verziu klasického indexového cyklu. Oproti Parallel.ForEach je vhodný tam, kde chcem pracovať s indexami. To znamená, že iterácie od 0 po data.Length - 1 sa rozdelia medzi viaceré vlákna. Každá iterácia spracuje jeden prvok poľa podľa indexu i. Potom nasleduje dôležitý variant s nastaveniami, vytvorí sa var options. Nastavujeme tu vlastnosť MaxDegreeOfParallelism, ktorú odovzdáme ako argument do Parallel.For. MaxDegreeOfParallelism určuje horný limit počtu súbežne vykonávaných pracovných jednotiek. Praktický dopad je, že viem robiť kontrolované experimenty s 2, 4 alebo 8 vláknami a sledovať speedup.
7. Paralelné spracovanie pomocou Task¶

Note 7
Tu ide o konštrukciu založenú na Tasks s možnosťou pracovať asynchrónne. Tento prístup je vhodný vtedy, keď nechcem len rozdeliť cyklus, ale potrebujem explicitne vytvárať samostatné úlohy a potom čakať na ich dokončenie. Postup je takýto: vytvárame zoznam tasks. V cykle pridávame úlohy pomocou Task.Run. Vo vnútri sa vytvorí lokálna premenná int local = i, keby som ju nepoužil, všetky tasky by mohli pracovať s rovnakou zdieľanou hodnotou i, ktorá sa v cykle mení. Na konci metódy sa volá Task.WhenAll(tasks), ktorá asynchrónne počká na dokončenie všetkých vytvorených taskov. Zároveň ale neplatí jednoduché pravidlo „10 taskov = 10 vlákien“. Task je logická jednotka práce, nie fyzické vlákno. Runtime sa rozhodne, koľko fyzických vlákien reálne použije. Výhodou je, že pri asynchrónnom čakaní neblokujeme vlákno, ktoré tak môže vykonávať inú prácu.
8. Paralelné spracovanie pomocou PLINQ¶

Note 8
PLINQ, teda Parallel LINQ, nám umožňuje paralelizovať spracovanie dát pomocou funkcionálneho zápisu. Kód vyzerá takto: vstupom je pole int[] data, návratová hodnota je nové pole data. Kľúčovým momentom je volanie metódy AsParallel(), ktoré povie, že ďalšie operácie nad kolekciou sa majú spracovať paralelne. Select(Compute) aplikuje funkciu Compute na každý prvok. ToArray() zhromaždí výsledky do poľa. PLINQ sa hodí hlavne na čisté transformácie dát.
9. Synchronizácia vlákien - štruktúry a synchronizátory¶
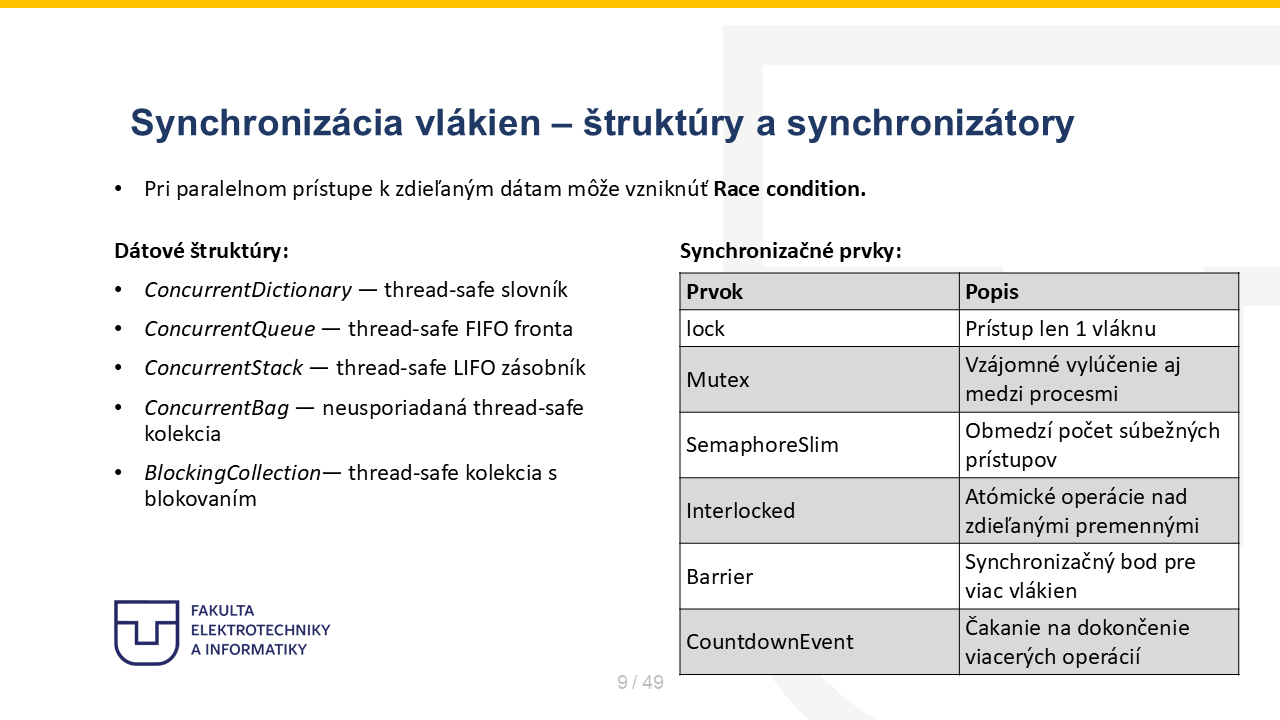
Note 9
Doteraz som ukazoval hlavne prípady, kde iterácie boli nezávislé. Teraz sa pozrieme na situáciu, keď viaceré vlákna pristupujú k spoločným dátam. Kľúčový problém pri paralelnom prístupe k zdieľaným dátam je race condition. To znamená, že výsledok závisí od poradia vykonania jednotlivých vlákien. Ak viac vlákien naraz číta a zapisuje tú istú premennú alebo štruktúru bez ochrany, môžem dostať nekorektný výsledok. Na slide sú dve skupiny nástrojov. Prvá skupina sú thread-safe dátové štruktúry. .NET ponúka špeciálne kolekcie v mennom priestore System.Collections.Concurrent, ktoré sú takzvané thread-safe, teda kolekcie navrhnuté tak, aby s nimi mohlo bezpečne pracovať viac vlákien naraz bez toho, aby sme museli všetko ručne zamykať napr. pomocou lock(). Napríklad ConcurrentDictionary alebo ConcurrentQueue umožňujú viacerým vláknam zapisovať a čítať súčasne bez toho, aby došlo k poškodeniu vnútornej štruktúry. Druhá skupina sú synchronizačné primitíva. lock pustí do kritickej sekcie len jedno vlákno. Mutex je podobný, ale dá sa použiť aj medzi procesmi, používa sa, keď potrebuješ synchronizovať nielen vlákna, ale aj celé aplikácie medzi sebou. SemaphoreSlim obmedzuje počet súbežných vstupov. Interlocked slúži na atómické operácie nad jednoduchými premennými. Barrier a CountdownEvent sú skôr koordinačné mechanizmy medzi viacerými vláknami. Hlavná myšlienka je, že paralelizácia bez správnej synchronizácie môže síce zrýchliť výpočet, ale zároveň zničiť korektnosť výsledkov. Na ďalších troch slidoch ukážem konkrétne spôsoby synchronizácie.
10. Paralelné spracovanie pomocou lock¶

Note 10
Ako prvý synchronizačný mechanizmus si ukážeme lock na synchronizáciu prístupu k zdieľanému počítadlu int _counter. Bez ochrany by operácia counter++ nebola bezpečná, pretože sa skladá z viacerých krokov - načítanie hodnoty, zvýšenie a zápis späť. Najprv sa vytvorí synchronizačný objekt pomocou Sync = new(), ktorý slúži ako zámok. Parallel.For spustí veľa iterácií paralelne. Keď vlákno príde k príkazu lock(Sync), skontroluje, či je zámok voľný. Ak áno, zamkne ho, vykoná inkrementáciu _counter++ a odomkne. Ostatné vlákna musia pred zámkom čakať. Nevýhodou je, že lock je pomerne drahá operácia a pri príliš veľkom počte vlákien môže dôjsť k degradácii výkonu, pretože vláknam v podstate nanucujeme sekvenčný beh.
11. Paralelné spracovanie pomocou semaphore (async)¶

Note 11
Modernejšou a často efektívnejšou alternatívou k locku v asynchrónnom prostredí je semafor pomocou SemaphoreSlim v kombinácii s async/await, ktorý povoľuje nie jedno, ale viac súbežných vstupov bez blokovania vlákien. Hlavná idea je, že nechcem pustiť všetky tasky naraz, ale len určitý počet súčasne - v tomto prípade 4. Potom sa v cykle foreach vytvárajú tasky a pridávajú sa do kolekcie tasks. Vnútri každého tasku await Semaphore.WaitAsync(); task asynchrónne čaká, kým sa uvoľní jedno miesto v semafore. Dôležité je, že pri WaitAsync sa vlákno zbytočne neblokuje. Počas čakania môže runtime vlákno využiť na inú prácu. try { Compute(item); } - po získaní vstupu do semafora sa vykoná výpočet. Po vykonaní výpočtu v finally bloku uvoľníme zámok cez Release(). await Task.WhenAll(tasks); - na konci sa čaká na dokončenie všetkých taskov. Toto je vysoko efektívny model pre I/O operácie. Využívame asynchrónnosť na maximum a zároveň chránime náš systém pred preťažením.
12. Paralelné spracovanie pomocou semaphore (sync)¶

Note 12
Teraz ukážem ten istý princíp obmedzenia paralelizmu, ale v synchronnej verzii bez async/await. Hoci samotný algoritmus zostáva identický, zásadný rozdiel spočíva v spôsobe čakania. Rozdiel je v tom, že namiesto asynchrónneho čakania sa používa klasické blokujúce čakanie. To znamená, že keď vlákno čaká na vstup, je počas čakania obsadené a nemôže robiť inú prácu. Pri WaitAsync čaká task bez blokovania vlákna, pri Wait čaká priamo vlákno. Výsledný efekt je síce rovnaký - stále úspešne kontrolujeme maximálny počet súčasne bežiacich výpočtov - ale robíme to za cenu nižšej efektivity. Toto riešenie je náročnejšie na systémové prostriedky, pretože namiesto efektívneho uvoľnenia vlákna ho nechávame nečinne blokované.
13. Úloha 3: Mandelbrot set¶

Note 13
V tejto časti prejdem od všeobecnej teórie k praktickej úlohe, na ktorej ukážem reálny prínos paralelizácie. Ako príklad som zvolil generovanie Mandelbrotovej množiny, pretože ide o výpočtovo náročný problém, kde sa dá veľmi dobre pozorovať rozdiel medzi sekvenčným a paralelným spracovaním.
14. Čo je Mandelbrotova množina¶

Note 14
Mandelbrotova množina je matematický objekt a jeden z najznámejších fraktálov. Je to súbor bodov v komplexnej rovine, ktoré vytvárajú nekonečne zložitý a vizuálne fascinujúci obraz. Vzniká iteratívnym výpočtom funkcie. Kľúčová myšlienka je, že pre každý bod c skúmam, či iterácia zostane ohraničená, alebo začne divergovať do nekonečna. Ak neunikne, bod považujem za súčasť Mandelbrotovej množiny. Hlavné vlastnosti fraktálu sú nekonečná zložitosť, sebapodobnosť a nekonečná hĺbka detailu. To znamená, že pri približovaní stále nachádzame nové štruktúry, ale základný princíp výpočtu ostáva rovnaký. Keď si priblížite okraj množiny, uvidíte, že sa tie isté zložité tvary opakujú stále dokola v nekonečných detailoch.
15. Ako funguje Mandelbrotov algoritmus¶

Note 15
Tu je popísaný základný postup. Iterácia začína hodnotou z₀ = 0. Potom opakovane počítam vzťah zₙ₊₁ = zₙ² + c, kde c je pevne zvolený bod komplexnej roviny. Počas výpočtu sledujem veľkosť hodnoty z. Ak absolútna hodnota prekročí 2, viem, že bod diverguje a nepatrí do Mandelbrotovej množiny. Ak ani po stanovenom počte iterácií neprekročí hranicu, beriem ho ako bod patriaci do množiny. Čím vyšší počet iterácií nastavím, tým viac práce musí procesor vykonať.
16. Divergencia a správanie iterácií¶
Note 16
Na tomto slide vidíme vizualizáciu Mandelbrotovej množiny. Dôležité je, že tmavá oblasť predstavuje body, ktoré do množiny patria, alebo pri danom limite iterácií neunikli. Okolité farebné oblasti predstavujú body mimo množiny, pričom farba zvyčajne závisí od toho, ako rýchlo bod divergoval.
17. Mandelbrotova množina v komplexnej rovine¶
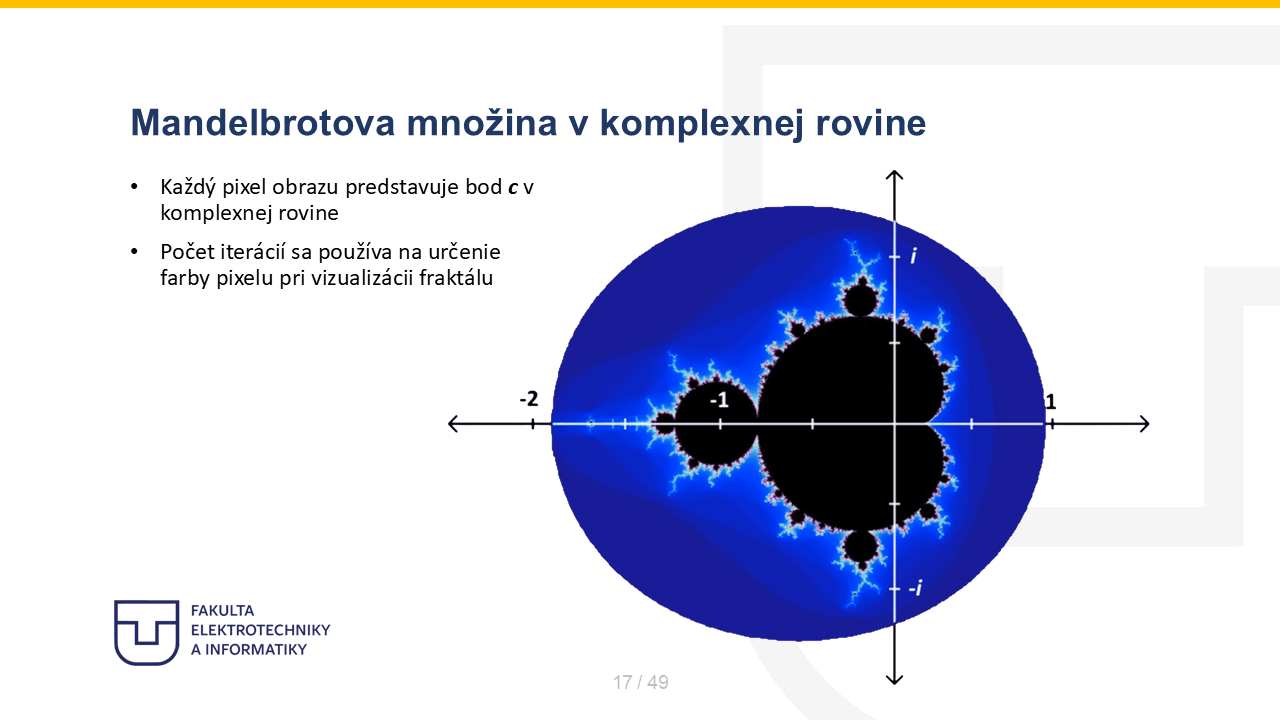
Note 17
Poďme sa teraz pozrieť na to, ako presne sú pixely na vašej obrazovke previazané s bodmi v komplexnej rovine. Je dôležité si uvedomiť, že v tomto kontexte pre nás obrazovka nie je len obyčajná bitmapa, ale diskrétna reprezentácia matematického priestoru. V praxi to znamená, že každý jeden pixel reprezentuje konkrétne komplexné číslo c. Pre každý tento bod spustíme iteračný algoritmus, ktorý testuje, ako sa dané číslo správa. Práve počet iterácií, po ktorých bod „unikne“ do nekonečna, určuje výslednú farbu pixelu. Bod, ktorý diverguje okamžite, dostane inú farbu než ten, ktorý sa dlho drží na hranici množiny. Implementačne to teda vyžaduje presný prevod: horizontálnu a vertikálnu pozíciu pixelu prepočítame na reálnu a imaginárnu zložku komplexného čísla. Výsledkom tohto spojenia kódu a matematiky je potom ten detailný fraktálny obraz, ktorý vidíte.
18. Nastavenie experimentu a hardvérová konfigurácia¶

Note 18
Na tomto slide uvádzam experimentálne nastavenie. Pri hľadaní optimálneho výkonu som postupoval podľa tohto trojstupňového modelu. V prvom kroku som vytvoril sekvenčnú implementáciu, ktorá slúži ako referenčný bod. Bez nej by sme nevedeli objektívne posúdiť, či a o koľko sme náš algoritmus neskôr zrýchlili. Následne prišlo na rad profilovanie pomocou nástroja AMD µProf, ktorý ukázal, ktorá časť algoritmu najviac vyťažuje CPU a je vhodná pre paralelné spracovanie. Na základe týchto tvrdých dát som v treťom kroku pristúpil k samotnej paralelnej implementácii. Programovací jazyk je C#. Testovali sa rozlíšenia od 800 × 600 až po 3840 × 2160 a počty iterácií 500, 1000, 2000 a 5000. Zároveň boli použité 2 warmup iterácie a 5 benchmark iterácií. Warmup je dôležitý najmä v .NET prostredí kvôli JIT kompilácii a ustáleniu výkonu, aby merania neboli skreslené prvotným štartom. Hardvér tvorí AMD Ryzen 7 8840HS, 16 GB DDR5 RAM, integrovaná grafika AMD Radeon 780M, 8 fyzických jadier a 16 vlákien. Práve počet vlákien priamo ovplyvňuje, aký priestor má paralelná implementácia na zrýchlenie.
19. Vstup / Výstup¶

Note 19
Naľavo vidíme vstupné parametre výpočtu Mandelbrotovej množiny. Nastavujem tu šírku a výšku obrazu, maximálny počet iterácií, stred zobrazenej oblasti v komplexnej rovine a tiež mierku, teda aký výrez fraktálu sa bude počítať. Okrem toho sú tam aj benchmark parametre, konkrétne počet warmup behov, počet ostrých meraní a prepínač, či sa má použiť sekvenčný alebo paralelný režim. Pri paralelnom režime ešte nastavujem počet vlákien. V strede a napravo je výstup aplikácie. Prvým výstupom je pole iterácií pre všetky pixely, z ktorého sa následne vytvorí bitmapa Mandelbrotovej množiny. To je ten samotný obrázok fraktálu. Druhým výstupom sú benchmark výsledky, kde vidíme časy jednotlivých behov a medián pre paralelnú aj sekvenčnú verziu.
20. Sekvenčná implementácia¶

Note 20
Výpočet prebieha postupne riadok po riadku a pixel po pixeli. Každý pixel sa najprv namapuje na bod v komplexnej rovine [c = x0 + y0i] a potom sa pre tento bod vo while cykle počíta počet iterácií Mandelbrotovej funkcie, kým bod neunikne alebo sa nedosiahne maximálny počet iterácií. Výsledok sa uloží do poľa data, ktoré obsahuje iterácie pre všetky pixely obrazu. V mojom kóde je to realizované vo funkcii ComputeMandelbrot(...) cez dvojitý for cyklus. Praktický dôsledok je ten, že implementácia je jednoduchá a prehľadná, ale pri vyššom rozlíšení a väčšom počte iterácií je už výpočtovo pomalá, pretože všetko beží len na jednom vlákne.
x0, y0: súradnice bodu c v komplexnej rovine pre aktuálny pixel, teda reálna a imaginárna časť čísla c
[x0 = startX + px * step, y0 = startY + py * step, c = x0 + y0 * i]
x, y: aktuálna hodnota iterovaného komplexného čísla z, kde x je reálna časť a y imaginárna časť
[z = x + y * i, z0 = (x = 0.0, y = 0.0)]
step, scale, width: veľkosť jedného pixelu v komplexnej rovine, v obraze sa posunieš o 1 pixel, v matematickej rovine sa posunieš o step.
scale hovorí, akú širokú časť komplexnej roviny chceš zobraziť. width hovorí, na koľko pixelov túto šírku rozdelíš.
[step = scale / width]
startX, startY: súradnice ľavého horného rohu zobrazenej oblasti v komplexnej rovine
[startX = centerX - (width / 2.0) * step, startY = centerY - (height / 2.0) * step]
px, py: súradnice aktuálneho pixelu v obraze, kde px je stĺpec a py je riadok
[for (int py = 0; py < height; py++), for (int px = 0; px < width; px++)]
rowOffset: index začiatku aktuálneho riadku v 1D poli data
[rowOffset = py * width]
z² + c: hlavný Mandelbrotov iteračný vzťah, podľa ktorého sa počíta nová hodnota z
[y = 2.0 * x * y + y0, x = xx - yy + x0]
21. Profilovanie sekvenčnej verzie¶
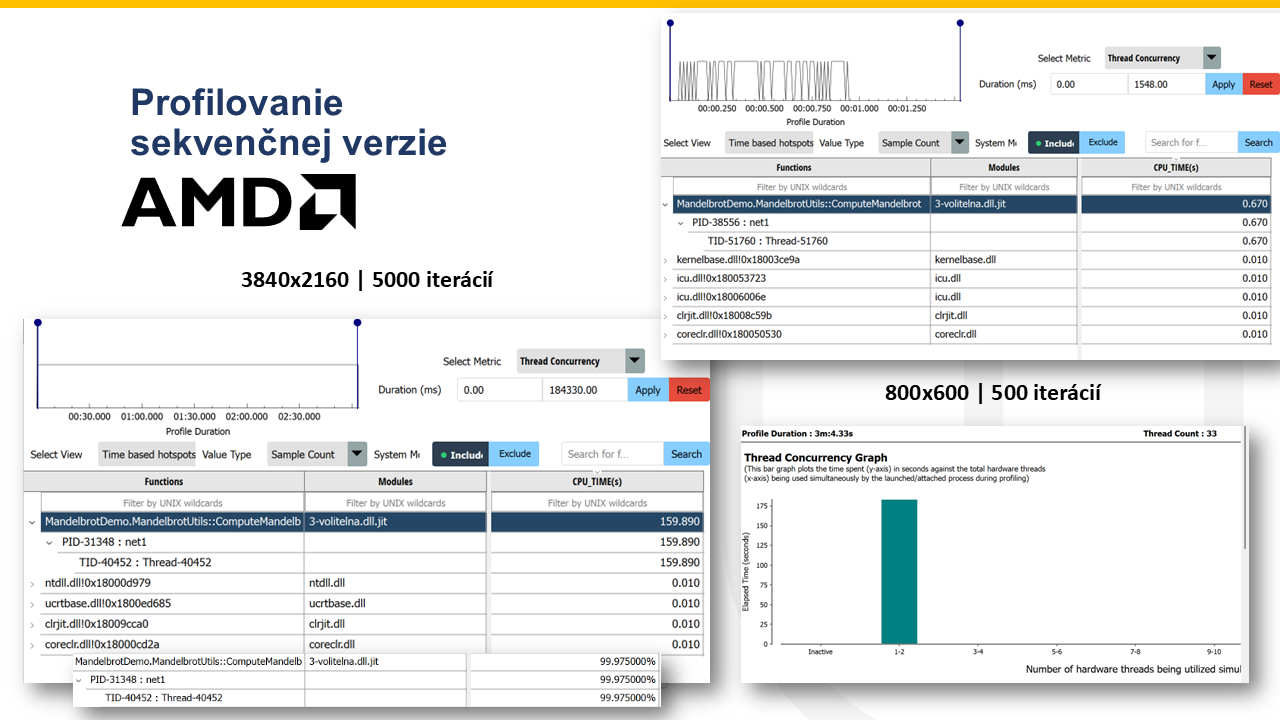
Note 21
Na tomto slajde je zobrazená profilácia sekvenčnej implementácie algoritmu pomocou nástroja AMD µProf. Profilovanie bolo vykonané na všetkých rozlíšeniach a iteráciách. Z výsledkov profilácie je možné vidieť, že dominantná časť výpočtového času je strávená v metóde ComputeMandelbrot, ktorá predstavuje približne 99 % celkového CPU času. To znamená, že práve táto časť algoritmu je hlavný výpočtový bottleneck programu. Histogram využitia CPU zároveň ukazuje, že počas vykonávania programu je väčšinu času využívané iba jedno procesorové jadro, čo potvrdzuje, že implementácia je čisto sekvenčná a nevyužíva potenciál viacjadrového procesora. Na základe tejto analýzy môžeme usúdiť, že najväčší potenciál optimalizácie spočíva v paralelizácii výpočtu Mandelbrot algoritmu, konkrétne v samotnom výpočte iterácií nad pixelmi.
22. Profilovanie paralelnej verzie¶
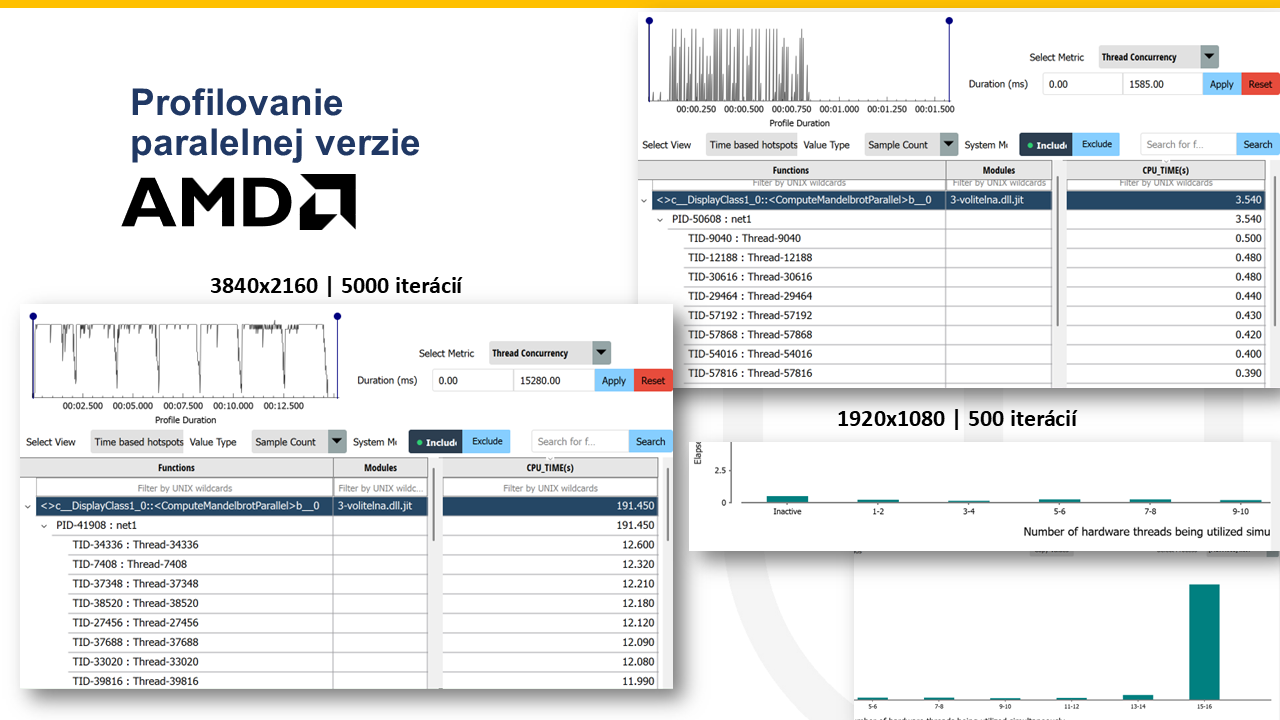
Note 22
Tu vidíme profiláciu paralelnej verzie pre 4K rozlíšenie a 16 vlákien. Rovnako ako pri sekvenčnej implementácii, aj tu je hlavným hotspotom samotný výpočet Mandelbrotu, teda metóda ComputeMandelbrotParallel. Rozdiel je ale v tom, že CPU čas už nie je sústredený na jednom jadre. V profile vidíme, že práca je rozdelená medzi viacero worker threadov a graf concurrency ukazuje, že počas väčšiny behu je využívaných približne 15 až 16 hardvérových vlákien naraz. To potvrdzuje, že paralelizácia naozaj funguje a algoritmus vie efektívne využiť viacjadrový procesor. Zároveň sú časy jednotlivých threadov pomerne podobné, čo znamená, že záťaž je rozdelená relatívne rovnomerne a nevzniká výrazná nevyváženosť práce.
23. Paralelná implementácia¶

Note 23
Na tomto slide ukazujem, ako sa rovnaký výpočet dá zrýchliť pomocou paralelizácie. Samotná matematika algoritmu sa nemení, stále počítam Mandelbrotovu funkciu pre každý pixel, ale mení sa spôsob vykonávania. Namiesto sekvenčného spracovania všetkých riadkov používam Parallel.For, ktorý rozdelí riadky obrazu medzi viac vlákien. Každé vlákno spracúva svoj riadok a zapisuje výsledky do vlastnej časti poľa data, takže tu nevzniká konflikt pri zápise a nie je potrebná synchronizácia. V kóde sa to nastavuje cez ParallelOptions a MaxDegreeOfParallelism, kde určujem počet vlákien. Výhodou je, že .NET runtime rozdeľuje prácu automaticky a keď jedno vlákno skončí skôr, môže pokračovať ďalším nespracovaným riadkom. Praktický dôsledok je výrazné skrátenie času výpočtu bez potreby ručne spravovať vlákna.
24. Výsledky meraní¶
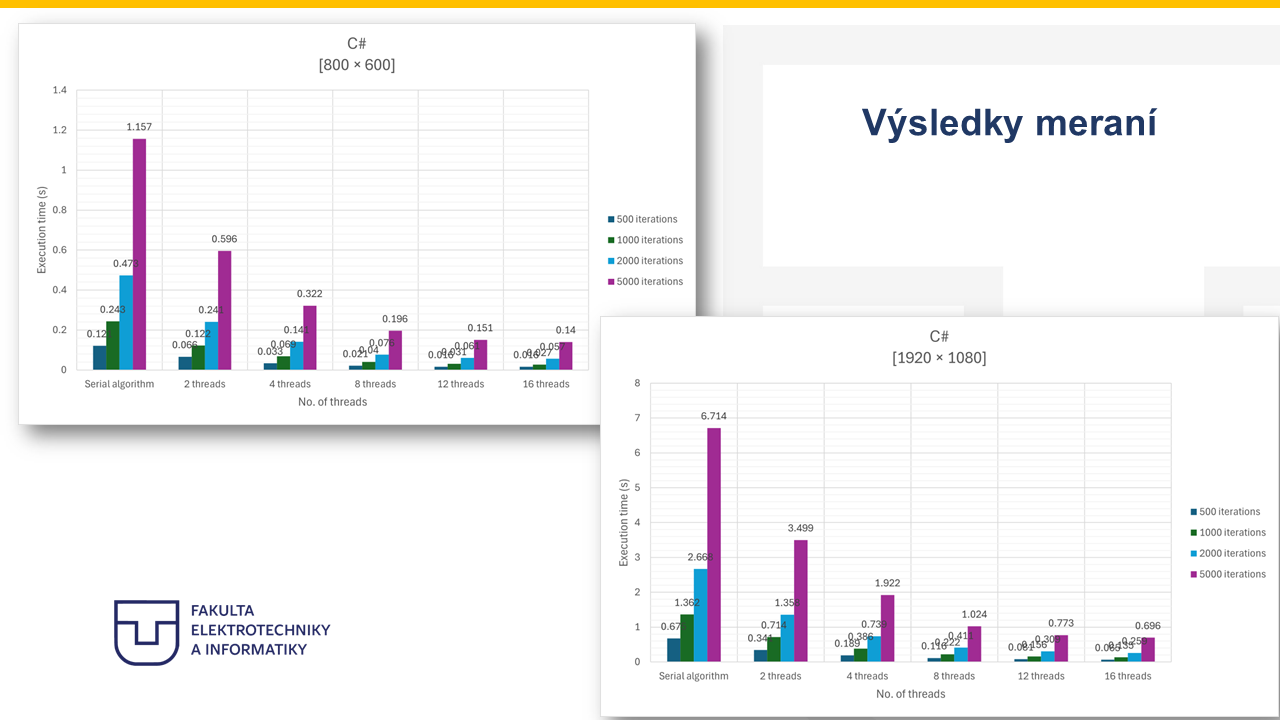
Note 24
Na týchto grafoch sú zobrazené výsledky merania času spracovania mandelbrot algoritmu v závislosti od počtu vlákien pre rozlíšenie 800 × 600 a FHD. Na horizontálnej osi je počet použitých vlákien a na vertikálnej osi je medianový čas spracovania v milisekundách. Graf zároveň zobrazuje výsledky pre všetky testované iterácie - od 500 až 5000. Z výsledkov je možné vidieť, že so zvyšujúcim sa počtom vlákien sa čas spracovania postupne znižuje, čo potvrdzuje efektívnosť paralelizácie algoritmu. Zároveň je však z grafu vidieť, že najväčší pokles času nastáva pri nižších počtoch vlákien, najmä pri prechode zo sekvenčného výpočtu na 2 alebo 4 vlákna. Pri vyšších počtoch vlákien sa výkon stále zlepšuje, zároveň je viditeľné, že pri vyšších počtoch vlákien sa zlepšenie výkonu postupne spomaľuje. Tento efekt je spôsobený najmä overheadom spojeným so správou vlákien a obmedzeniami paralelizácie, čo je bežné pri paralelných algoritmoch. Takisto je možné pozorovať, že pri väčších rozlíšeniach je absolútny čas spracovania výrazne vyšší, avšak paralelizácia prináša výraznejší prínos, pretože množstvo spracovávaných dát je podstatne väčšie.
25. Výsledky meraní¶
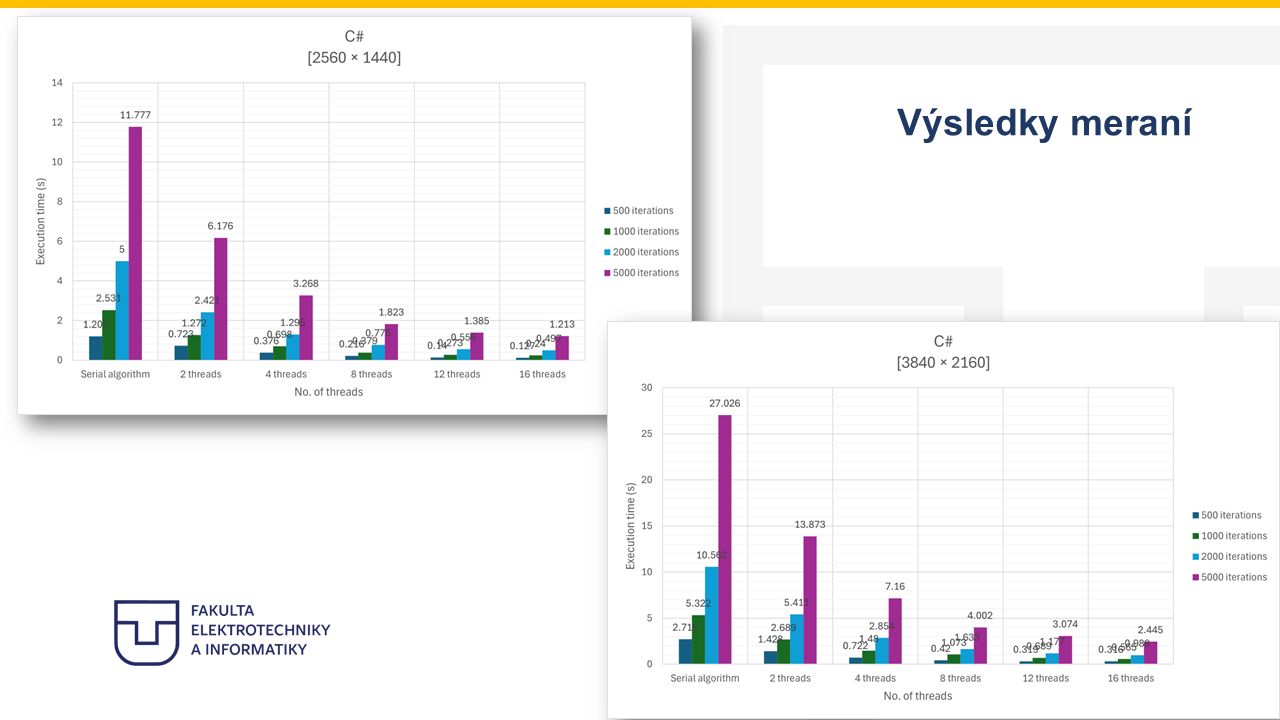
Note 25
Na týchto grafoch sú zobrazené výsledky merania času spracovania mandelbrot algoritmu v závislosti od počtu vlákien pre rozlíšenie 4K a 2K. Na horizontálnej osi je počet použitých vlákien a na vertikálnej osi je medianový čas spracovania v milisekundách. Graf zároveň zobrazuje výsledky pre všetky testované iterácie - od 500 až 5000. Z výsledkov je možné vidieť, že so zvyšujúcim sa počtom vlákien sa čas spracovania postupne znižuje, čo potvrdzuje efektívnosť paralelizácie algoritmu. Zároveň je však z grafu vidieť, že najväčší pokles času nastáva pri nižších počtoch vlákien, najmä pri prechode zo sekvenčného výpočtu na 2 alebo 4 vlákna. Pri vyšších počtoch vlákien sa výkon stále zlepšuje, zároveň je viditeľné, že pri vyšších počtoch vlákien sa zlepšenie výkonu postupne spomaľuje. Tento efekt je spôsobený najmä overheadom spojeným so správou vlákien a obmedzeniami paralelizácie, čo je bežné pri paralelných algoritmoch. Takisto je možné pozorovať, že pri väčších rozlíšeniach je absolútny čas spracovania výrazne vyšší, avšak paralelizácia prináša výraznejší prínos, pretože množstvo spracovávaných dát je podstatne väčšie.
26. Výsledky meraní¶
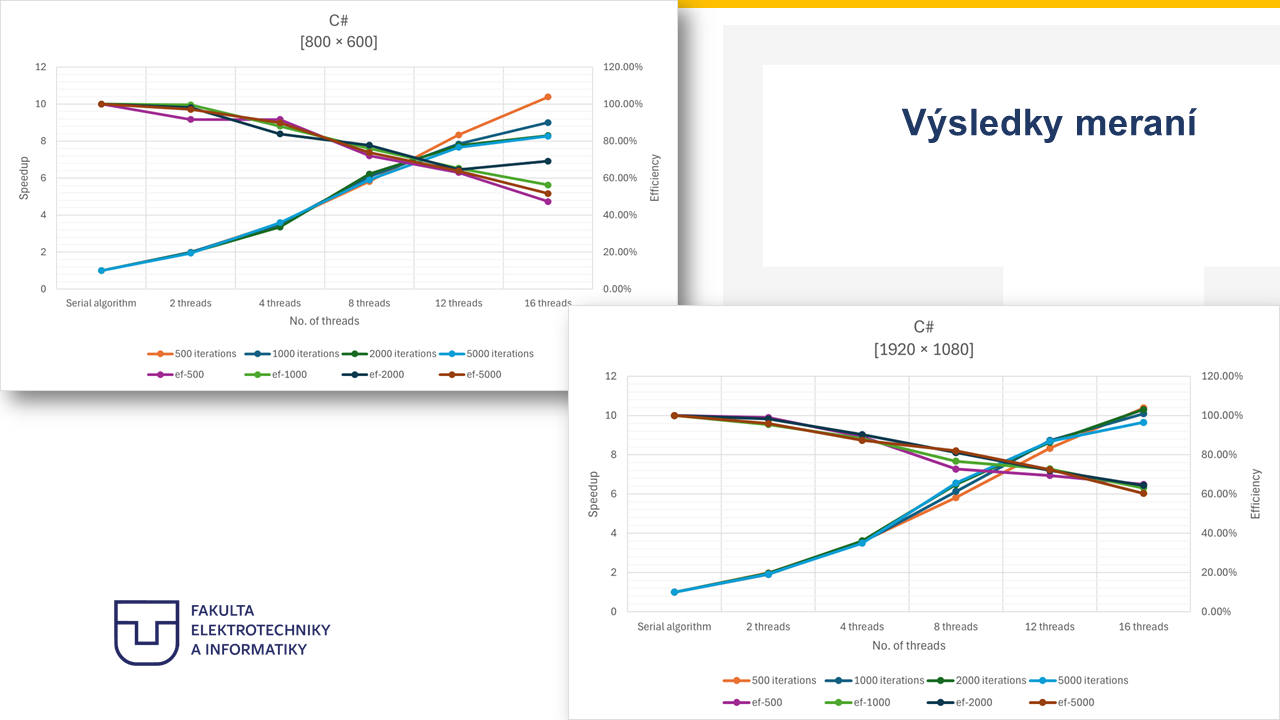
Note 26
Na týchto grafoch sú zobrazené výsledky zrýchlenia a efektivity paralelného algoritmu v závislosti od počtu vlákien a iterácií. Na ľavej osi je znázornené zrýchlenie, teda speedup, ktoré vyjadruje, koľkokrát je paralelná implementácia rýchlejšia v porovnaní so sekvenčnou verziou. Na pravej osi je zobrazená efektivita využitia vlákien, ktorá vyjadruje, ako efektívne sú jednotlivé vlákna využívané pri paralelnom spracovaní. Z grafu je vidieť, že so zvyšujúcim sa počtom vlákien dochádza k postupnému zvyšovaniu zrýchlenia algoritmu, pričom najvyššie zrýchlenie dosahujeme pri použití 16 vlákien. Tento efekt je výraznejší najmä pri väčších rozlíšeniach, kde je výpočtová záťaž väčšia. Na druhej strane môžeme pozorovať, že efektivita paralelizácie postupne klesá so zvyšujúcim sa počtom vlákien. Tento jav je typický pre paralelné algoritmy a je spôsobený najmä režijnými nákladmi, ako je správa vlákien, plánovanie úloh alebo prístup do pamäte. Celkovo však výsledky ukazujú, že paralelizácia mandelbrot algoritmu prináša výrazné zrýchlenie spracovania obrazu, najmä pri spracovaní veľkých dátových objemov.
27. Výsledky meraní¶
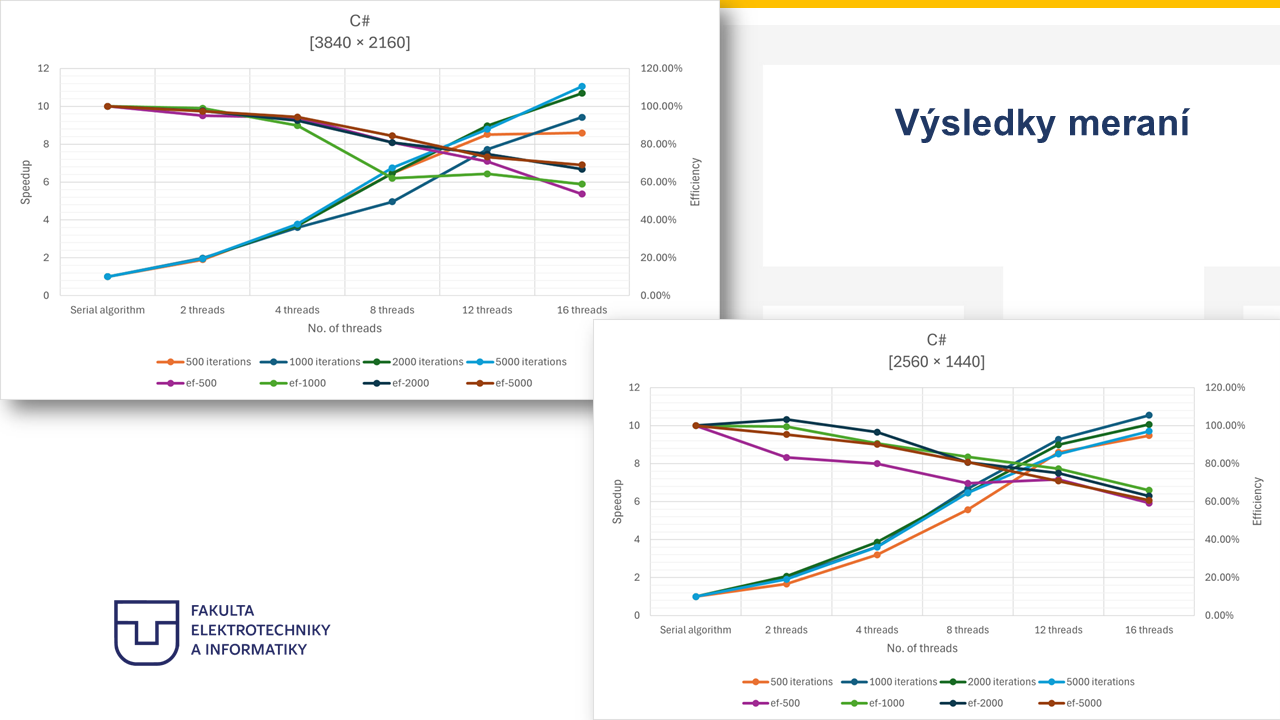
Note 27
Na týchto grafoch sú zobrazené výsledky zrýchlenia a efektivity paralelného algoritmu v závislosti od počtu vlákien a iterácií. Na ľavej osi je znázornené zrýchlenie, teda speedup, ktoré vyjadruje, koľkokrát je paralelná implementácia rýchlejšia v porovnaní so sekvenčnou verziou. Na pravej osi je zobrazená efektivita využitia vlákien, ktorá vyjadruje, ako efektívne sú jednotlivé vlákna využívané pri paralelnom spracovaní. Z grafu je vidieť, že so zvyšujúcim sa počtom vlákien dochádza k postupnému zvyšovaniu zrýchlenia algoritmu, pričom najvyššie zrýchlenie dosahujeme pri použití 16 vlákien. Tento efekt je výraznejší najmä pri väčších rozlíšeniach, kde je výpočtová záťaž väčšia. Na druhej strane môžeme pozorovať, že efektivita paralelizácie postupne klesá so zvyšujúcim sa počtom vlákien. Tento jav je typický pre paralelné algoritmy a je spôsobený najmä režijnými nákladmi, ako je správa vlákien, plánovanie úloh alebo prístup do pamäte. Celkovo však výsledky ukazujú, že paralelizácia mandelbrot algoritmu prináša výrazné zrýchlenie spracovania obrazu, najmä pri spracovaní veľkých dátových objemov.
28. Záver¶
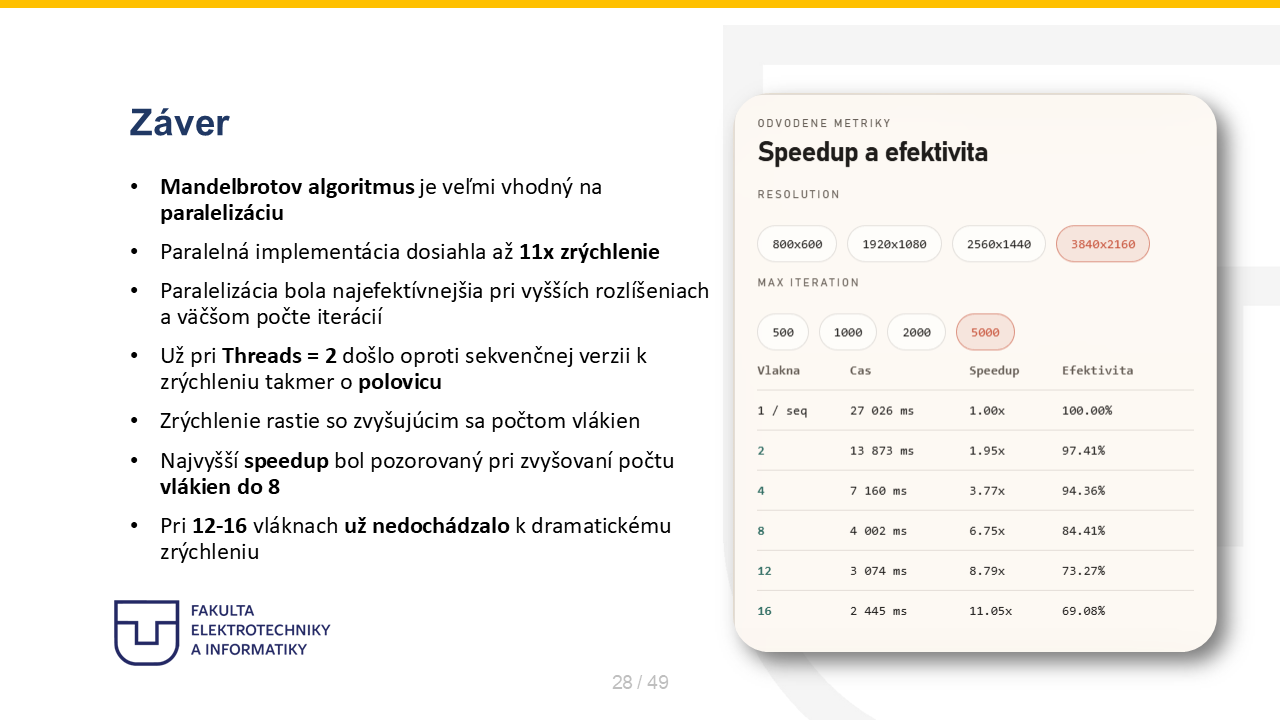
Note 28
Na záver tu vidíme, že Mandelbrotov algoritmus je na paralelizáciu veľmi vhodný, pretože jednotlivé riadky obrazu sa dajú počítať nezávisle. Už pri dvoch vláknach sa čas výrazne znížil a pri konfigurácii 4K s 5000 iteráciami klesol zo zhruba 27 sekúnd na približne 2,4 sekundy pri 16 vláknach, čo je asi 11-násobné zrýchlenie. V tabuľke zároveň vidíme, že speedup rastie so zvyšujúcim sa počtom vlákien, ale efektivita postupne klesá, čo je pri paralelných programoch bežné. Najväčší prínos bol približne do 8 vlákien, potom sa zrýchlenie už zvyšovalo pomalšie. Z môjho pohľadu teda projekt potvrdil, že Parallel.For je v C# veľmi vhodný nástroj na riešenie takýchto dátovo paralelných úloh.